40K Current Army Meta – LVO 2017



Today take a look at what armies are hot and who’s note in the 40K meta. You’ll be shocked!
An article written by Variance Hammer
As has become something of a yearly tradition here at Variance Hammer, I’ve done some number crunching on the 2017 Las Vegas Open 40K Championships, to see what there is to see.
And this year, what there is to see is interesting. A king has been unseated, to be replaced by pirates, renegades and daemons.
The Data:
The data used for this analysis is an unholy union of the tournament results found on Best Coast Pairings, last year’s LVO results (we’ll get to that in a minute), and the dump of ITC scores from this January I used for this post. The latter we assume is a reasonable standin for someone’s ITC score as they go into the LVO – not perfect, as there were some tournaments in very late January, but probably reasonable. I’ll get the dataset up on the Variance Hammer Github site soon, but that is in need of a major reorganization after the past few months.
Army Representation: The factions present at the LVO were a pretty broad swathe, with all the usual players there in force.
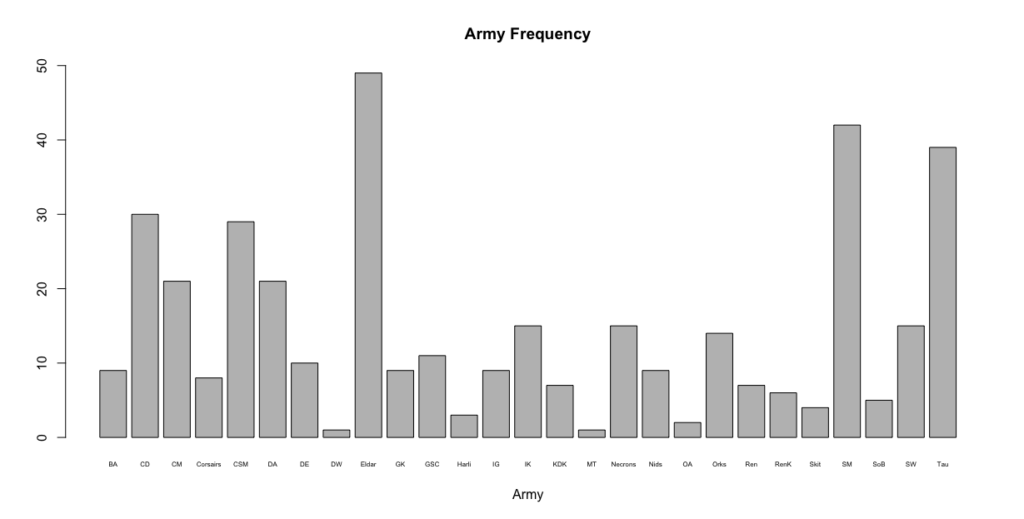
That’s a tiny picture, I know. By far the best represented were the Eldar, followed by Space Marines and Tau, with strong showings from Chaos Daemons, Chaos Space Marines, Cult Mechanicus, and the Dark Angels. This is pretty much the same as we saw last year. The singleton armies this year were Deathwatch and Militarum Tempestus. There’s somewhat middling numbers of everything else, and it’s good to see less powerful codexes getting played, though there are clearly some tournament favorites.
Player/Tournament Scene Contributions:
I’ve recently begin trying to more accurately estimate the role of a player in the performance of their army, rather than just the army itself. After all, there’s probably a wider difference between me playing Eldar and the top ranked ITC Eldar player than there is between a top ranked ITC Eldar player and a top ranked ITC Chaos Daemons player.
If by probably I mean “certainly”.
I tried to get at this a little bit with my analysis of Warzone Atlanta, but was flummoxed a bit by two issues. First, because WZA had grown a lot, many of the players there hadn’t played in the previous Warzone Atlanta, which meant I couldn’t really use “How did you do at the last one?” as a measure. Second, a lot of the folks in that region don’t seem to heavily attend ITC events, which made their ITC score nigh useless.
The LVO has neither one of these problems. I’ll model them both when I look at army performance, but let’s take a look for a moment at how well your incoming ITC score correlates with your battle points at the event:
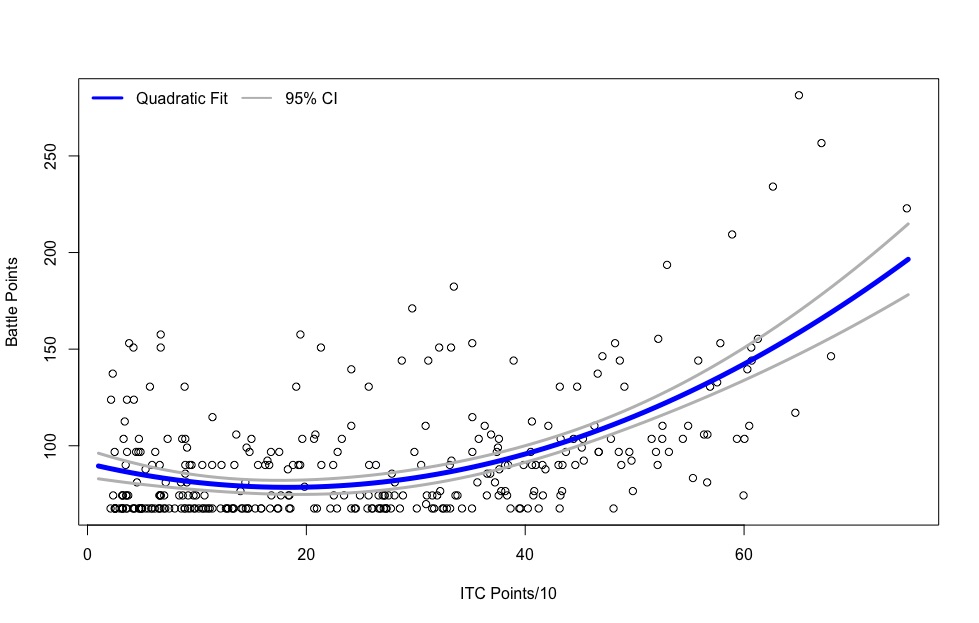
Nicely, but not perfectly. Like the “Events Attended and ITC Points” correlation, it’s a nice quadratic fit – basically more ITC points is exponentially better, and there’s few really high performing players with almost no ITC points. On the other hand, there’s some very well ranked ITC players who had a very bad weekend from a performance standpoint.

An Aside for Math Lovers….
Now, lets also control for army performance (discussed below) to parse out just the effect of player skill independent of the army they chose. First, a brief statistical aside. I decided to jointly model both player characteristics (placing at LVO 2016 and incoming ITC points) and army selection at the same time, but a fair number of people are missing an LVO 2016 placing, and a smaller number are missing ITC points. Conventionally, the solution to this is to throw out anyone with missing values (this is called “complete case analysis”). Its bad for a number of reasons I won’t get into, but this year, I’ve used something called multiple imputation to handle that missing data problem. This is why, if you just rerun the model using my data on another machine you’re likely not going to get the same answer. /end statistical nerdery.
For the LVO, as they use non-integer battle points, I used a linear regression model, so rather than these modifiers being a multiplier of your score, this time they’re an addition to your score. For example, the “average” army is estimated to get a BP score of 103.95, and the modifier for a the Dark Eldar is 1.68, which means a Dark Eldar army statistically can expect a BP score of (103.95+1.68) or 105.63. Positive scores are good, negative scores are bad, and if everyone had a score of zero, it would mean army selection/player skill didn’t matter.
Controlling for army selection, the relationship between placement and ITC points remains largely the same, with a linear term of -0.94 and a quadratic term of 0.03 for ITC points divided by ten. What does that mean? It means that someone with 100 ITC points is expected to have (-0.94*10) + (0.03*10^2) or -6.4 BP below the average score, while someone with 450 ITC points is expected to have (-0.94*45) + (0.03*45^2) or 18.45 BP above the average score. That’s a fairly significant portion of what determines performance.
AdvertisementI also looked at previous LVO performance, which showed a pretty predictable linear trend of -0.13, meaning for each place lower in the 2016 40K Championships you placed, you could be expected to earn 0.13 less BPs. So the different between someone who placed 10th and someone who placed 60th last year? The model predicts the 60th ranked player will earn -0.13 * (60-10) or -6.5 BP compared to their 10th ranked opponent. Back to normal speak…

Army Performance:
Now let’s consider army performance while controlling for player skill. The short version: Renegades won. Or well, kinda Renegades. A Renegades CAD along with Fateweaver, the Masque, and a Heralds Anarchic formation. We’re going to get to this later- “What does a faction at this point even mean?”
Importantly, in the Top 10 results, there were only three Eldar players overall, one each for Craftworld, Corsair and Dark Eldar, which makes me chuckle a little bit. And this is where things get interesting: This year, the Eldar were not particularly good.
That is not to say they’re bad. Oh no. But in terms of the way I’ve been modeling army performance recently, as how much an army can expect to have it’s score modified over an “average” army based on army selecting, they fared only middling well. Shall we look at them all? Below is easy army’s modifier, along with a 95% confidence interval for those who care about these things:
- Chaos Daemons: 14.77 (0.56, 28.97)
- Cult Mechanicus: 0.32 (-13.32, 13.95)
- Eldar Corsairs: 25.70 (5.52, 45.88)
- Chaos Space Marines: 1.19 (-9.97, 12.36)
- Dark Angels: 14.47 (-0.38, 29.32)
- Dark Eldar: 1.68 (-16.86, 20.23)
- Deathwatch: 9.01 (-7.69, 25.72)
- Eldar: 4.68 (-5.90, 15.26)
- Grey Knights: 9.77 (-6.81, 26.35)
- Genestealer Cult: 1.73 (-18.19, 21.64)
- Harlequins: 11.93 (-3.96, 27.84)
- Imperial Guard: -4.81 (-17.72, 8.11)
- Imperial Knights: 0.54 (-11.99, 13.07)
- Khorne Daemonkin: 22.57 (4.89, 40.26)
- Militarum Tempestus: 24.79 (15.61, 33.97)
- Necrons: -6.59 (-18.16, 4.99)
- Tyranids: 1.89 (-10.14, 13.92)
- Assassins: -7.83 (-40.37, 24.70)
- Orks: -5.41 (-18.85, 10.73)
- Renegades: 19.17 (-16.02, 54.36)
- Renegade Knights: 2.89 (-13.26, 19.04)
- Skitarii: -4.06 (-8.16, 14.12)
- Space Marines: 2.98 (-8.16, 14.12)
- Sisters of Battle: -7.30 (-28.64, 14.03)
- Space Wolves: 15.55 (0.59, 30.51)
- Tau: 0.19 (-11.54, 11.93)
Some Interesting Things to Note
Craftworld-primary Lists Weren’t Particularly Strong: While Craftworld lists were better than average, they weren’t by very much, and pretty firmly in the realm of many other books. This comes as a surprise compared to previous years, where Craftworld lists were indisputably the strongest lists there. There was evidence they were slipping when I looked at WZA’s results as well, and it’s pretty strong here. This was, in some ways, inevitable. The Craftworld Eldar have been strong for well over an entire edition now and highly overrepresented in the tournament scene, which creates a very strong selective pressure toward armies that can deal with the Eldar. And it appears they have have arrived.
Interestingly, there seems to have been some flight toward more exotic Eldar lists, like Corsairs, among experienced players that have served them well.
Chaos is Fine Now: Renegades, Chaos Daemons and Khorne Daemonkin all made strong showings, and Chaos Space Marine primary lists still dwell in the “middling fair” category. I’ll have a more detailed post on this (hopefully) soon, but the recent additions to the overall Chaos faction have done good things for them.
The Variability of the Tau: The Tau are the army parked most firmly in “middling-okay” territory in the LVO data, which is an interesting contrast to WZA where they were the strongest single faction there. To my mind, this comes down in its entirety to whether or not the Ta’unar Supremacy Suit is legal. That single decision has a huge impact on the performance of this faction, and says some very bad things about the balance of that particular unit.
Exotic Space Marines > Gladius: Like the Craftworld Eldar, the Gladius has been a feature of the tournament circuit for a long time, and it seems that the meta has adapted to promote armies that can deal with it. Both the Space Wolves and Dark Angels, the cornerstones of more exotic “Deathstar” style builds well outperformed their codex counterparts.
The Great Devourer Isn’t Delivering: Reading the Genestealer Cults codex, many commentators saw a lot of potential in their special rules. This doesn’t seem to be manifesting itself as tournament performance. It’s possible that they’re the type of list that’s “preying” on some of the generic point-and-click Craftworld lists, like Scatterbike Spam, but that this doesn’t carry them into the upper tiers. Or its possible that their awesome special rules aren’t enough to carry them through having somewhat middling stats overall. This remains to be seen.
The Performance of Prediction As with WZA, I wanted to see how well these models actually predict the results of the tournament – could something like this be used for forecasting? Below is a plot of the actual results of the tournament compared to that predicted by the model:
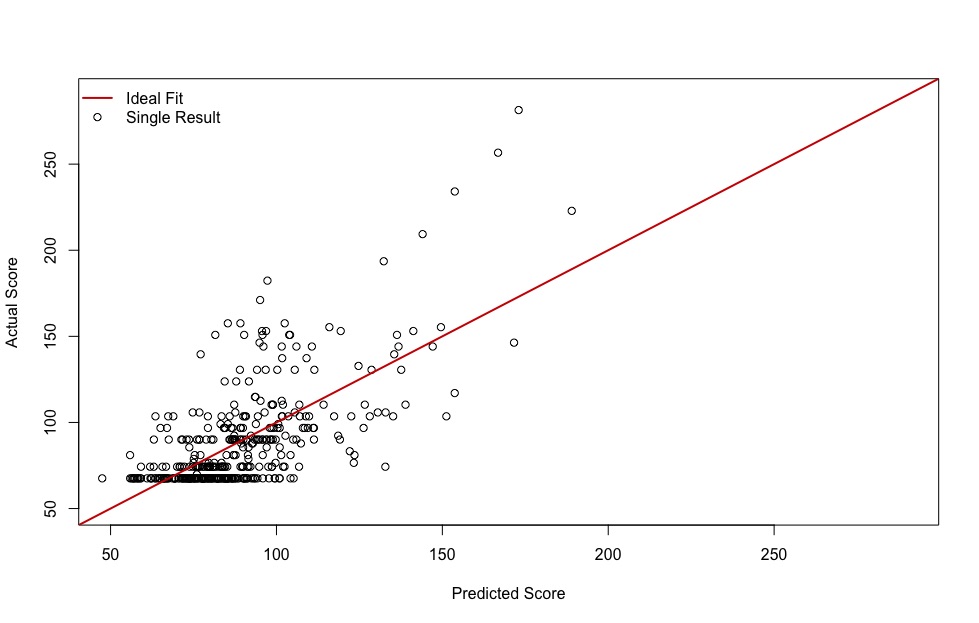
This is a vast improvement over the Warzone Atlanta model (primarily due to being able to build in more player-based characteristics), but still far from perfect. The red line would be perfect performance – the predicted score perfectly matching the actual score for each player. This model is fairly good at predicting most results in the tournament. And while it doesn’t nail the final results, it does a decent job. The predicted winner is in the top four actual results, and the actual winner of the LVO is similarly highly ranked in the predicted model. Predicting the winner like this does somewhat create what one might call the “Nate Silver Problem” – just because your model predicts an outcome is less likely, if it occurs that doesn’t mean you were wrong, just like if you fail a 2+ armor save it doesn’t mean it’s not better than a 4+.
There’s still room for improvement here, and I’m interested in working on a more match-based probabilistic model, but I’m decently happy with the results. There is, however, a looming problem…

What Does Faction Mean?
7th Edition has been one, continuous exercise in undermining the concept of a single codex army – culminating in the new Gathering Storm books, which just toss it entirely. Many of the top armies in the tournament, including the winners, were pretty Pick-n-Mix. So is it meaningful to call Lion’s Blade army with a Wolfstar a DA or SW army? Or an army with zombies and artillery from the Renegades list, a bunch of daemons, etc. – how truly is an “Assorted Chaos” army assigned to Renegades, Daemons, etc.? Yet something like “Chaos Daemons” is already imprecise – this could be a summoning heavy list, or a disastrously poor Daemonette-spam army. Merging anything further, into something like “Chaos”, “Imperial”, “Eldar” etc. threatens to wash out any nuance at all.
To be honest, I’m not yet sure how to handle this. Going down to list specifics is too cumbersome for what is, in essence, a hobby project, and would still involve subjectivity in deciding where to draw the line between what makes one list different from another. For the moment, primary faction seems a workable enough compromise.





