Teaching 304 Matchboxes To Beat You At Tic-Tac-Toe


The real Menace here is having to play hundreds of games of tic-tac-toe.
If you’re at all into keeping up with emerging technologies, you’ve probably heard about machine learning. It’s just a broad term for different ways we can teach machines things and stuff. Rather, how they can teach themselves. There are many types of machine learning and we won’t go into crazy detail on it, but for now the basic idea is this:
- Play a game against a computer.
- The computer picks moves randomly.
- The computer loses (probably) and learns to stop picking those moves in those situations.
- Rinse and repeat.
As this process iterates over and over and over, the ability of the computer to play the game better increases as it learns to stop making bad moves. This works much in the same way as Darwinian evolution: a random chance that works out well propagates into future evolutions.
The main driving force for this method, which is broadly called Neural Evolution, is that you have to be very specific in what you tell the computer its goal is. My favorite example of this is a team used this method to teach an AI to play Tetris and told it to “Get points and not lose for as long as possible”. After a short time, the computer was on the brink of losing and the game paused and did not unpause. By permanently pausing the game, the computer could forever avoid losing. The AI had figured that out on it own and if that’s not some super unnerving Wargames type logic, I don’t know what is.
 The only winning move is to actually make lines, you dumb computer.
The only winning move is to actually make lines, you dumb computer.
So, neat. But why are we talking about this?
Because this is exactly how 304 matchboxes were taught to play Tic-Tac-Toe.

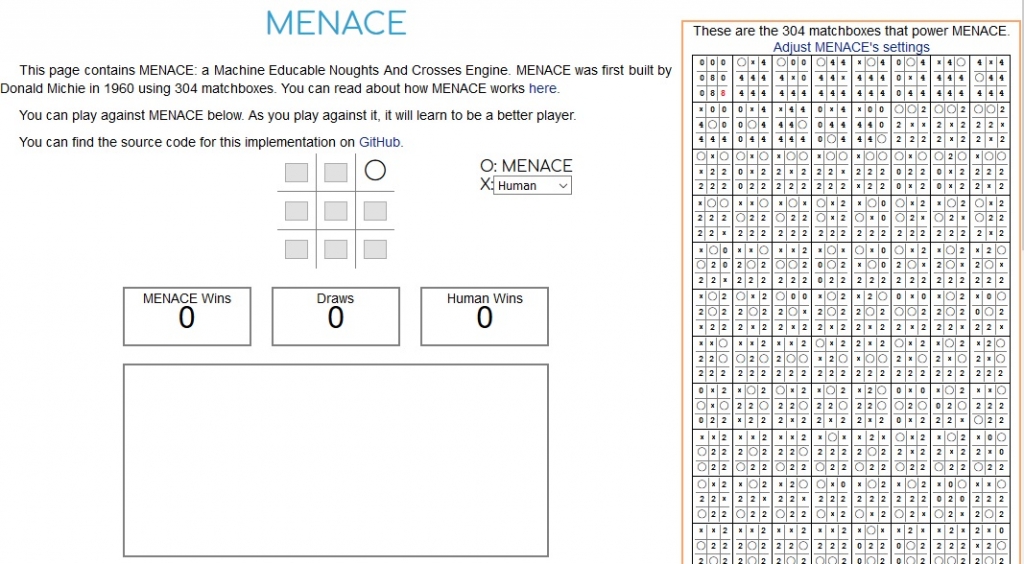
Back in 1960, Donald Michie came up with the idea for Menace (Machine Educable Noughts And Crosses Engine). Michie had helped break the German Tunny code in WWII and had a knack for cryptography and machine learning, before that was even a thing!
Menace is comprised of 304 match boxes which are each labeled with a specific game state.

Within each box is a bead (or bean), which dictates which move Menace will make. Red bead indicates upper left, blue means center right, etc. Each box gets 1 bead for each of the possible moves for that game state. Each time Menace makes a move, a bead is pulled out randomly to determine which move will be made. Those beads and boxes are set aside for learning once the game is over. If Menace loses, the beads that were chosen are removed from the boxes. This ensures Menace is less likely to make that move in future games, or not at all if all the beads of that color are removed. If Menace wins, additional beads of that color are added to the box, ensuring Menace will be more likely to make those moves in the future.
And that’s basically it! After playing hundreds of games, Menace can almost guarantee to not lose. Which is pretty impressive considering it’s nothing but a pile of match boxes and beads. And also considering, it (as a computer) was never actually taught how to play Tic-Tac-Toe.
You can play against an online version of Menace and watch the evolutions yourself right here.
Glad to be back!
Thanks for reading!



